
type
status
date
slug
summary
tags
category
icon
password
我最近对网络爬虫颇有兴趣,在 AI 领域不断取得的新进展也激发了我尝试开发一款能持续检索网络内容直到找到目标信息的“全能”爬虫。这个项目还在进行中,但我想分享一下目前的进展情况。
项目规格
基于一个起始网址和一个宏观目标,这个网络爬虫应该能够:
- 分析指定网页
- 从相关部分提取文本信息
- 进行必要的互动操作
- 重复上述步骤直至实现目标
工具选择
虽然这是个纯后端项目,我还是选择了 NextJs 来构建,以便日后可能会加上前端界面。对于网页爬取库,我选择了 Crawlee,它基于 Playwright(一种浏览器自动化库)提供了包装器。Crawlee 为浏览器自动化增加了额外功能,使爬虫更易于伪装成普通用户。他们还提供了一个便捷的请求队列来管理请求顺序,这在我想把这个工具部署给他人使用时非常有用。
在 AI 方面,我使用了 OpenAI 的 API 和 Microsoft Azure 的 OpenAI 服务。我共使用了三种不同的模型:
- GPT-4-32k ('gpt-4-32k')
- GPT-4-Turbo ('gpt-4-1106-preview')
- GPT-4-Turbo-Vision ('gpt-4-vision-preview')
GPT-4-Turbo 模型在保持原有 GPT-4 特性的基础上,具有更大的上下文窗口(128k Token)和更快的速度(最高可达 10 倍)。但遗憾的是,这些改进牺牲了一些智能度:GPT-4-Turbo 比原版 GPT-4 略逊一筹。在我的爬虫项目的复杂阶段,这成了一个问题,因此我开始在需要更强大智能时使用 GPT-4-32K。
GPT-4-32K 是 GPT-4 的一个改进版本,其上下文窗口为 32k 而非原来的 4k。(我最终通过 Azure 的 OpenAI 服务来使用 GPT-4-32K,因为 OpenAI 目前限制了在他们平台上对该模型的访问)
项目启动
我是从面对的限制出发开始这个项目的。鉴于我底层使用的是 Playwright 爬虫,我知道如果要与网页进行互动,我最终需要从网页中提取一个元素选择器。
简单来说,元素选择器是一个字符串,用于识别网页上的特定元素。比如,如果我想选取页面上的第四段落,我可以用选择器 p:nth-of-type(4);如果我想选择一个写着“点击我”的按钮,我可以用选择器 button:has-text('Click Me')。Playwright 的工作原理是,首先用选择器找到你想互动的元素,然后对其执行动作,比如点击('click()')或填充('fill()')。
因此,我的首要任务就是找出如何从一个指定网页中识别“目标元素”。接下来,我会把这个功能称作“GET_ELEMENT”。
寻找目标元素的方法
方法 1:截图 + 视觉模型
HTML 数据通常既复杂又冗长,大部分用于定义样式、布局和交互逻辑,而非文本内容本身。我担心在这种情况下纯文本模型可能处理得不够好,所以我考虑利用 GPT-4-Turbo-Vision 模型来直接“观察”渲染后的网页,并从中提取最相关的文本。然后我再去原始 HTML 中查找包含这段文本的元素。

这个方法很快就遇到了问题:
首先,GPT-4-Turbo-Vision 有时会拒绝我的文本提取请求,比如说“对不起,我不能帮助你做这个。”它甚至说过“对不起,我不能从受版权保护的图片中提取文本。”显然,OpenAI 正试图阻止它完成这类任务。(不过,声明自己是盲人似乎可以绕过这个限制。)
接着出现了更大的问题:大型网页会生成非常高的截图(超过 8,000 像素)。这成了一个问题,因为 GPT-4-Turbo-Vision 在处理所有图片时会将它们调整到特定尺寸。我发现一个过高的图片会被压缩变形到难以识别。
解决这个问题的一种方法可能是分段扫描网页,对每个部分进行总结,然后将结果拼接起来。但是,OpenAI 对 GPT-4-Turbo-Vision 的调用频率限制意味着我需要建立一个排队系统来处理这个过程,这听起来相当棘手。
最后,仅依靠文本来反向工程出有效的元素选择器并不容易,因为你无法得知底层 HTML 的结构。基于这些原因,我决定放弃这种方法。
方法 2:HTML + 文本模型
文本模型 GPT-4-Turbo 的调用限制更宽松,考虑到其 128k Token 的上下文窗口,我尝试直接传入整个网页的 HTML,并请求模型识别关键元素。

尽管大多数情况下 HTML 数据能够适应,但我发现 GPT-4-Turbo 模型还是不够聪明,无法准确完成这项任务。它们常常识别错误的元素或提供过于泛化的选择器。
因此,我试图通过只保留 body 部分并移除 script 和 style 标签来简化 HTML,虽然这在一定程度上有所帮助,但仍然不够。看来,从整个网页中准确识别“相关”HTML元素对于语言模型而言是一个过于模糊和难以把握的任务。我需要一种方法来缩小范围,只留下几个元素供文本模型分析。
在尝试下一个方法时,我决定从人类解决此类问题的角度获取灵感。
方法 3:HTML + 文本搜索 + 文本模型
如果我要在网页上寻找特定信息,我会用“Control” + “F”搜索关键词。如果第一次没有找到,我会尝试不同的关键词,直到找到所需信息。
这种方法的优点在于,简单的文本搜索既快速又容易实现。在我的项目中,搜索词可以通过文本模型生成,搜索过程则可以用简单的正则表达式对 HTML 进行。
生成搜索词的过程比搜索本身要慢,所以我可以让文本模型一次性生成多个搜索词,然后同时进行搜索。所有包含搜索词的 HTML 元素将被汇集起来,用于下一步,我会请 GPT-4-32K 选择其中最相关的一个。

当然,如果使用的搜索词太多,有时会捕获大量 HTML,这可能触发 API 限制或影响下一步的性能,因此我设计了一个策略,能够智能地填充一个自定义长度的相关元素列表。
我让 Turbo 模型生成 15-20 个术语,并按相关性排序。然后,我通过简单的正则表达式搜索整个 HTML,找到页面上包含该术语的每个元素。这个步骤完成后,我得到了一个列表的列表,每个子列表包含匹配特定术语的所有元素:

接着,我开始填充最终列表,使用这些子列表中的元素,优先选择排名靠前的术语列表中的元素。比如说,排名的搜索术语是“定价(pricing)”、“费用(fee)”、“成本(cost)”和“价格(prices)”。填充最终列表时,我会确保从“定价”列表中选取更多元素,然后是“费用”列表,以此类推。
一旦最终列表达到预定的 Token 长度,我就停止添加。这样,我就能确保不会超过下一步的 Token 限制。

如果你对这个算法的代码感兴趣,这里有一个简化的版本:
这种方法让我最终得到了一个长度适中的列表,它包含了多种搜索术语的匹配元素,但优先考虑了相关性更高的术语。
然后出现了另一个问题:有时你需要的信息不在匹配元素本身,而是在其兄弟元素或父元素中。
假设我的 AI 正在寻找古巴的首都。它搜索“首都”一词,在橙色区域找到了一个元素。问题是我们需要的信息在绿色元素中 - 一个兄弟元素。我们已经接近答案了,但如果不同时包括这两个元素,我们就无法解决这个问题。

为了解决这个问题,我决定在我的元素搜索函数中包括“父元素”作为一个可选参数。设置父元素为 0 意味着搜索函数将只返回直接包含文本的元素(自然包括该元素的子元素)。
设置父元素为 1 意味着搜索函数将返回直接包含文本的元素的父元素。设置父元素为 2 意味着搜索函数将返回直接包含文本的元素的祖父元素,依此类推。在这个古巴的例子中,设置父元素为 2 将返回这整个部分的 HTML,如下图红色部分所示:
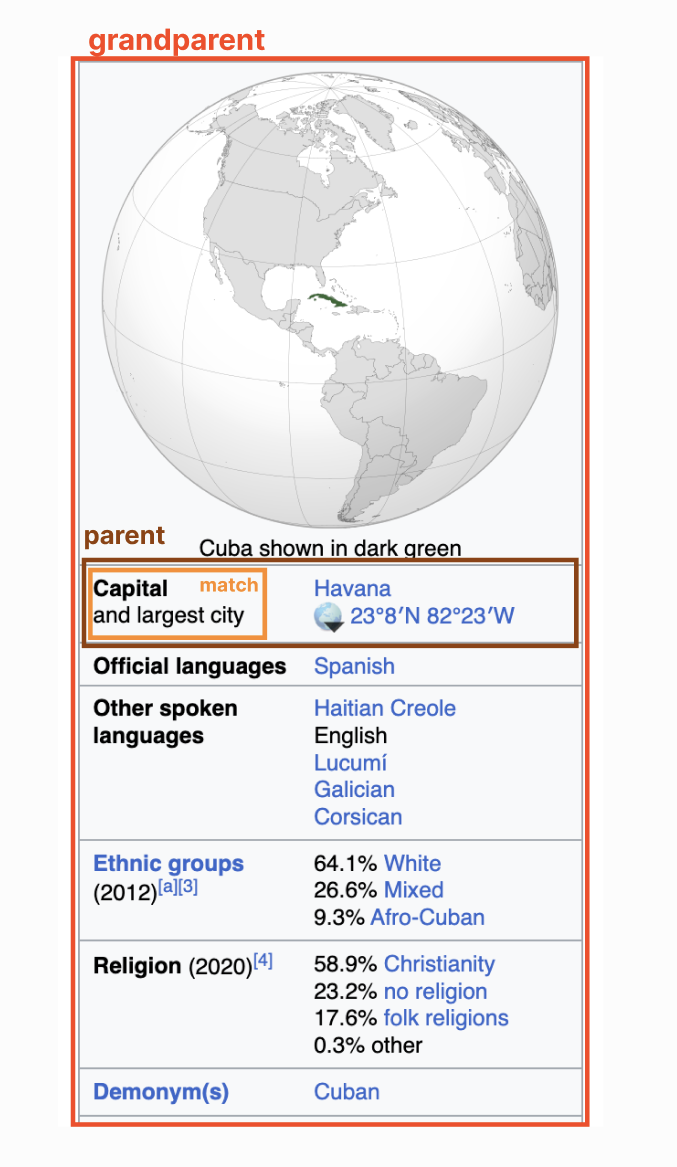
我决定将默认的父元素设置为 1。任何更高的设置,我可能会抓取到每次匹配的大量 HTML。
所以现在我们得到了一个大小可控、带有适量父元素上下文的列表,是时候进入下一步了:我想请 GPT-4-32K 从这个列表中选出最相关的元素。
这一步相当直接,但是需要一些尝试和错误来获得正确的提示:
完成这一步后,我将得到页面上单个最相关的元素,然后我可以将它传递给下一步,由一个 AI 模型决定为了实现目标需要进行什么类型的互动。
设置Assistant
提取相关元素的过程有效,但有点慢且随机。在这一点上,我需要一种“规划者”AI,它可以看到前一步骤的结果,如果效果不好,可以尝试使用不同的搜索术语再次尝试。
幸运的是,这正是OpenAI的Assistant API可以实现的。'Assistant'是一个包装在额外逻辑中的模型,允许它自主操作,使用定制工具,直到达到目标。您通过设置底层模型类型,定义它可以使用的工具列表,并发送消息来初始化它。
一旦Assistant正在运行,您可以轮询API以检查其状态。如果它决定使用自定义工具,状态将指示它希望使用的工具以及要使用的参数。这时,您可以生成工具输出并将其传递回Assistant,以便它可以继续。
对于这个项目,我建立了一个基于GPT-4-Turbo模型的Assistant,并为其提供了一个触发我刚刚创建的GET_ELEMENT函数的工具。
这是我为GET_ELEMENT工具提供的描述:
您会注意到,除了最相关的元素之外,该工具还返回每个提供的搜索术语的匹配元素数量。这些信息帮助Assistant决定是否需要尝试使用不同的搜索术语。
有了这个工具,Assistant现在能够解决我的规范的前两个步骤:分析给定的网页并从任何相关部分提取文本信息。在不实际与页面交互的情况下,这就足够了。如果我们想要知道产品的定价,而定价信息包含在我们的工具返回的元素中,Assistant可以简单地返回该元素的文本并完成。
然而,如果目标需要交互,Assistant将不得不决定要采取什么类型的交互,然后使用额外的工具执行它。我将这个额外的工具称为“INTERACT_WITH_ELEMENT”
与相关元素交互
为了制作一个与给定元素交互的工具,我认为我可能需要构建一个自定义API,该API可以将LLM的字符串响应转换为Playwright命令,但后来我意识到我正在使用的模型已经知道如何使用Playwright API(这是一个流行的库的好处!)。因此,我决定直接以异步立即调用的函数表达式(IIFE)的形式生成命令。
因此,计划变成了:
Assistant将提供要采取的交互的描述,我将使用GPT-4-32K编写该交互的代码,然后在我的Playwright爬虫中执行该代码。

这是我为INTERACT_WITH_ELEMENT工具提供的描述:
您会注意到,与其让Assistant完整写出元素,它只是提供了一个简短的标识符,这样更容易更快。
以下是我给GPT-4-32K的指示,帮助它编写代码。我希望处理可能存在需要在与之交互之前提取的页面上的相关信息的情况,因此我告诉它将提取的信息分配给一个名为'actionOutput'的变量。
我将从这一步得到的字符串输出 - 我称之为“动作” - 作为参数传递给我的Playwright爬虫,并使用'eval'函数将其作为代码执行(是的,我知道这可能是危险的):
如果你想知道为什么我不直接让Assistant提供其交互的代码,那是因为我用于Assistant的Turbo模型最终变得过于愚笨,无法可靠地编写命令。因此,我让Assistant描述它想要的交互(“点击这个元素”),然后我使用更强大的GPT-4-32K模型编写代码。
传递页面状态
在这一刻,我意识到我需要一种方式来向Assistant传递页面的状态。我希望它能够基于所在页面制定搜索词,而仅仅提供网址似乎不够理想。此外,有时我的爬虫未能正确加载页面,我希望Assistant能够检测到这一问题并进行重试。
为了获取这个额外的页面上下文,我决定创建一个新函数,利用GPT-4-Vision模型对页面的前2048像素进行总结。我在两个必要的地方插入了这个函数:在一开始,以便分析起始页面;以及在INTERACT_WITH_ELEMENT工具的结束时,以便Assistant能够理解其交互的结果。
有了这最后一块拼图,Assistant现在能够判断特定的交互是否按预期有效,或者是否需要重试。在出现验证码或其他弹出窗口的页面上,这非常有帮助。在这种情况下,Assistant将知道必须绕过障碍才能继续。
最终流程
让我们回顾一下到目前为止的整个过程:我们首先向Assistant提供一个URL和一个目标。Assistant然后使用'GET_ELEMENT'工具从页面中提取最相关的元素。
如果情况允许,Assistant将使用'INTERACT_WITH_ELEMENT'工具编写和执行与之交互的代码。它将重复这个流程,直到达到目标。
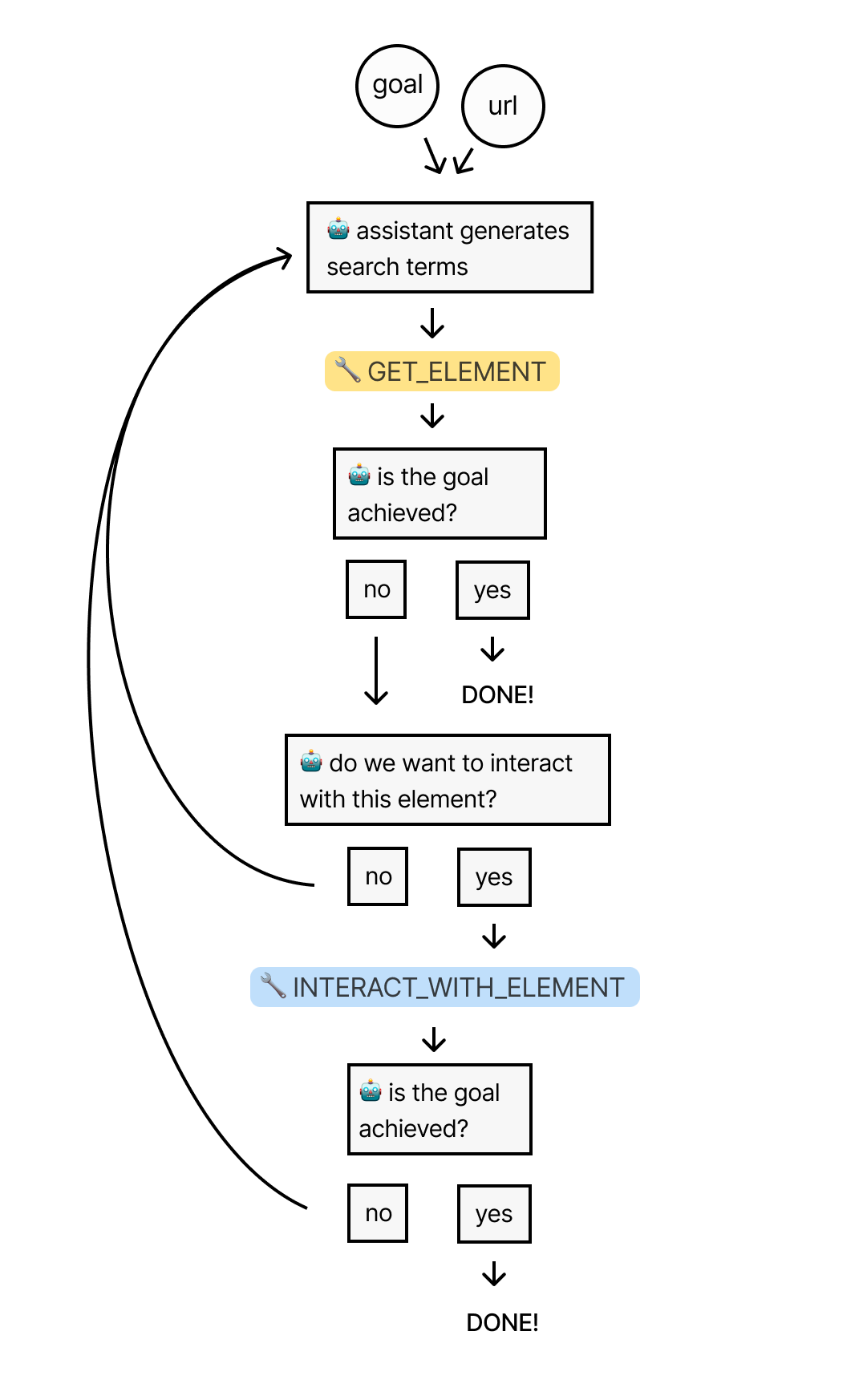
现在是时候将其放到测试中,看看它在维基百科中寻找答案时能够导航得如何。
测试Assistant
我的终极目标是构建一个能在每个页面上工作的通用网络爬虫,但作为起始测试,我想看看它在 Wikipedia 这种可靠环境中的表现如何,因为 Wikipedia 的每个页面都包含大量链接到许多其他页面。Assistant应该能够轻松在这个域中找到信息。
我给它提供了美国的 Wikipedia 页面,并告诉它:“我想知道莫哈韦沙漠的总土地面积。”
美国的页面包含近150万个字符的 HTML 内容,大致相当于375,000个 Token。因此,这将是一个测试系统处理大量数据能力的好方法。
正如预期的那样,Assistant使用了“GET_ELEMENT”工具,但它最初的搜索术语很差。这些术语可能太具体,无法在页面上找到确切的匹配项:
果不其然,工具在所有术语中找到了 0 个匹配项。
因此,Assistant决定再次尝试,这次它使用了更多、更通用的术语:
这次工具在这些术语中找到了134个匹配元素,总共超过3,000,000个 Token(可能是因为返回的元素之间有很多重叠)。幸运的是,之前提到的用于选择最终元素列表的算法能够将其缩减到41个元素(我设置的上限是10,000个 Token)。
然后,GPT-4-32K 选择了这个元素作为最相关的,其中包含了通往莫哈韦沙漠 Wikipedia 页面的链接:
如果你想知道为什么这个元素包含了除了链接本身之外的额外 HTML,那是因为我将“父元素”参数设置为 1,这意味着所有匹配的元素都将连同其直接父元素一起返回。
在作为“GET_ELEMENT”工具输出的一部分收到这个元素后,Assistant决定使用“INTERACT_WITH_ELEMENT”工具尝试点击那个链接:
“INTERACT_WITH_ELEMENT”工具使用 GPT-4-32K 处理这个想法,转换成 Playwright 动作:
我的 Playwright 爬虫运行了这个动作,浏览器成功导航到了莫哈韦沙漠页面。
最后,我用 GPT-4-Vision 处理了新页面,并将浏览器状态的摘要作为工具输出的一部分发送回Assistant:
Assistant决定目标尚未达成,因此在新页面上重复了这个过程。再次,它的最初搜索术语太具体,结果很少。但在第二次尝试中,它提出了这些术语:
“GET_ELEMENT”工具最初找到了21个匹配,总共491,000个 Token,被缩减到了12个。然后 GPT-4-32K 从这12个中选择了这个最相关的,其中包含搜索术语“km2”:
这个元素对应于渲染页面的这个部分:
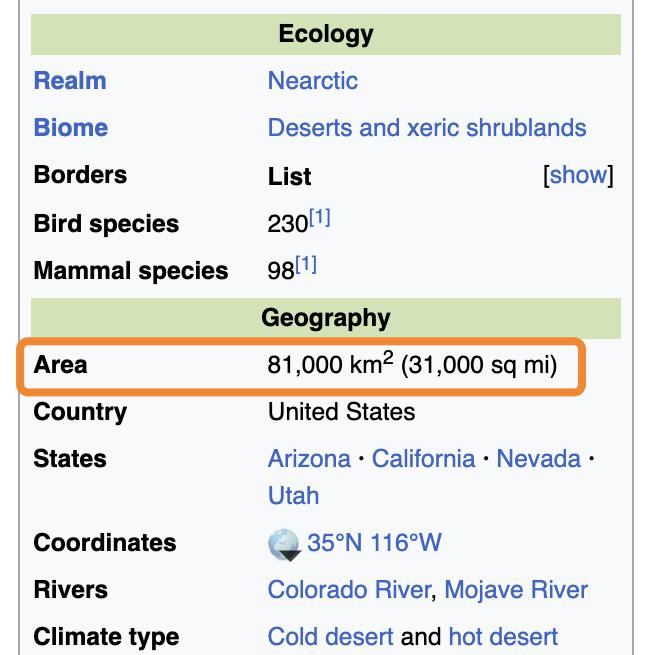
在这种情况下,如果我没有将“父元素”设置为 1,我们就无法找到这个答案,因为我们正在寻找的答案在匹配元素的兄弟元素中,就像我们的古巴例子一样。
“GET_ELEMENT”工具将元素传回给Assistant,Assistant正确地注意到其中的信息满足了我们的目标。因此,它完成了它的运行,告诉我莫哈韦沙漠的面积是81,000平方公里:
如果你想阅读这次运行的完整日志,你可以在这里找到它们的副本!
结束语
构建这个项目非常有趣,我也从中学到了很多。尽管如此,它仍然是一个易受影响的系统。我期待着将它发展到新的高度。以下是我想要改进的一些方面:
- 生成更精准的搜索术语,以便更迅速地定位到相关元素
- 在我的“GET_ELEMENT”工具中引入模糊搜索功能,以便处理文本中的微小差异
- 利用视觉模型来识别 HTML 中的图片和图标,让Assistant能够与之互动
- 通过居民代理和其他方法增强爬虫的隐蔽性
本文翻译自Tim Connors的文章《Building a Universal AI Scraper》
- 作者:荒岛游民
- 链接:https://huangdao.xyz/article/gpt-4-web-crawler-guide
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章